
The long time scale of my PhD means I have to deal with vastly different sources in my research. For the Gordon Riots (1780), I use mainly eyewitness accounts and court records. For the Battle of Cable Street (1936), I have access to images and videos of what happened. For the 2010 Student Tuition Fee Protests, the choices are almost endless. One of the sources I decided to utilise was Twitter, the social media website that allows its users to post updates of up to 140 characters. Every type of source presents different challenges for the researcher, and I found the unique challenges of Twitter rather difficult to cope with at first. This post is about the method I developed for my research, and I hope it will act as a catalyst for discussion amongst other scholars dealing with similar issues. My research was conducted on a computer with a Windows 10 operating system, and I do not know how well my method would translate to a different operating system.
Whilst there are programmes which collect tweets in real time as they are tweeted, many of which are open access, there are fewer designed to harvest pre-existing tweets. Those there are are aimed at a commercial rather than academic market, and their cost is beyond the scope of my research budget. So I had to develop my own ad-hoc, ‘low tech’ method of harvesting old tweets, using Twitter’s Advanced Search function.
In 2014 Twitter began allowing users to search for tweets more than 7 days old in its Advanced Search function (accessed from the options menu of a bog standard Twitter search result page, or by googling ‘Twitter Advanced Search’. You have to have a Twitter account to use this function). Advanced Search lets you combine a whole variety of search parameters, including date, location, hash tags, Twitter accounts, key words, sentiment (whether a Tweet is positive or negative). You can even input words you don’t want to be included.
Once I decided I was using Advanced Search, I had to decide on search parameters. The Student Tuition Fee Protests were a series of demonstrations, occupations and marches on both a national and local scale that took place between the 10th of November and the 9th of December 2010. I wanted to see Tweets from the four days of action that took place in London, on the 10th, 24th, and 30th of November, and the 9th of December. I started by searching for tweets that had been geotagged with London on the revelant days. Only a small percentage of tweets are geotagged, but it provided me with an idea of the hashtags and keywords that were were being used in regards to the demonstrations. I used this to decide on my search parameters. For example, for the demonstration on the 9th of December I searched for ‘Any of these words: protester, protesters, students, tuition, fees, protests’ and ‘These hashtags: #demo2010 #dayx3 #fees #solidarity #studentprotest #ukuncut’. For each demonstration, I used a slightly different combination of hashtags and keywords, in an attempt to find as many relevant tweets as possible. I acknowledge, however, that I probably did not find every tweet about the demonstrations. I also altered the dates as appropriate, then started the search.

Now for the long-winded part. I have not found a way to download multiple tweets at once. You can use your browser’s print function to save the search results as a pdf, but there are several disadvantages to this. You cannot expand the tweets to see what time they were tweeted, and it will only save the tweets that have loaded- you have to scroll all the way down to the bottom of the search results to save them all, and this can take a long time when searches yield more than a few thousand tweets. I did save the search results as a pdf, so I can go back to them at a later date if I want to, but only once I had read them all.
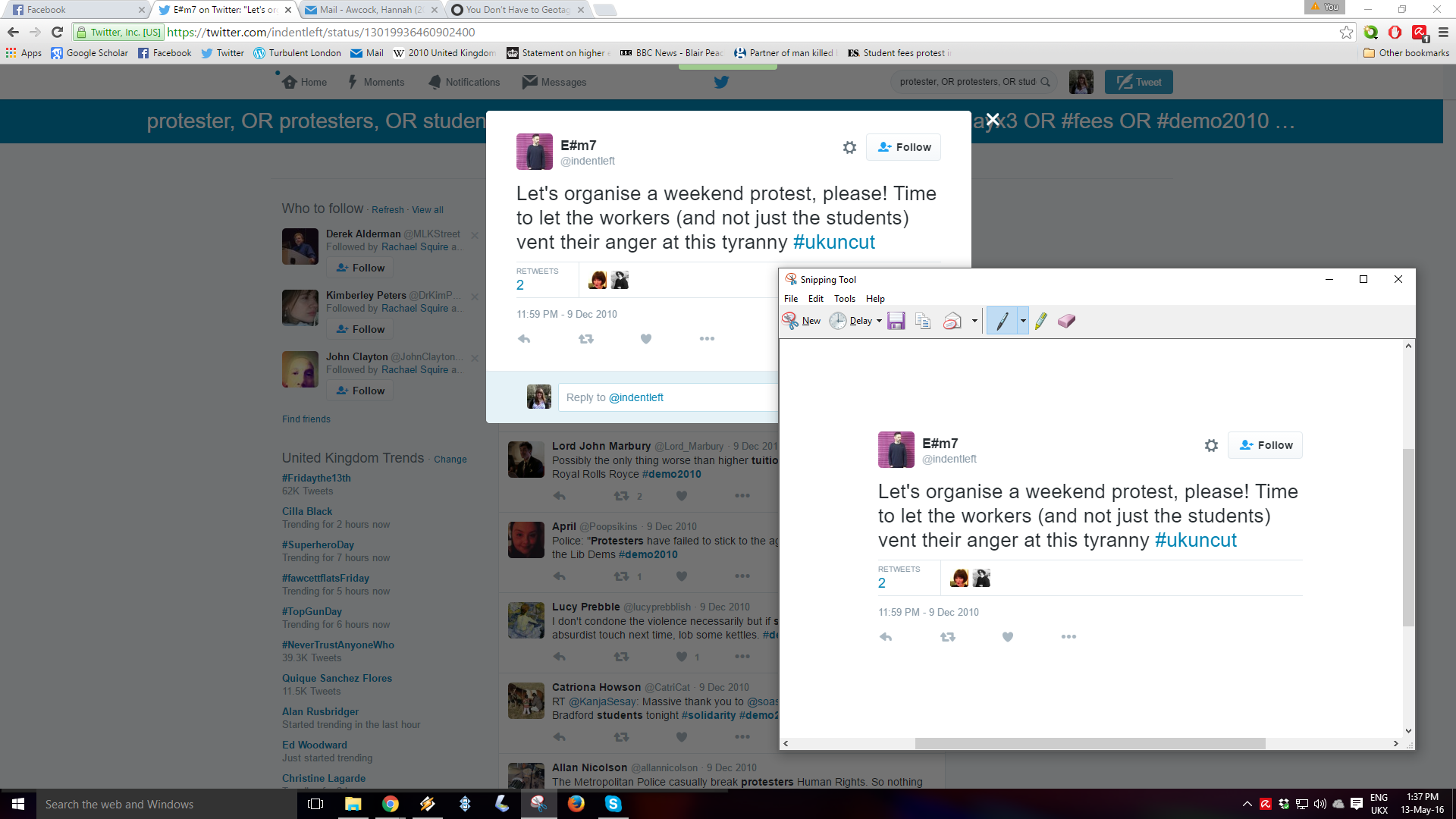
And that is how I analysed the search results, by reading every single tweet. Any tweets that I thought might be relevant to my research, I saved as a jpeg using the Snip tool, with it’s own individual number (001, 002, 003, 004 etc.). I also pasted each tweet into a word document, so I could go back to them later without having to open each individual jpeg. I coded the saved tweets as I went along, making a note of the tweet’s number and the key theme it related to. I also kept a count of how many tweets I had read as I went along. I wouldn’t say it was very reliable, but I can at least say roughly how many tweets I analysed for each demonstration. For example, I read almost 8000 tweets related to the demonstration on the 10th of November 2010.

So there you have it; my ad hoc, low tech (for Twitter!) method for collecting and analysing old Tweets for academic research. It is a rather clunky method, and I suspect that someone with more technological know-how than me could improve it dramatically, but it has allowed me to see how social media was being used during the 2010 Student Protests in London. If you have experience with this sort of research, or just have an opinion on it, then I would love to hear from you!

Great stuff Hannah. Nice to see another approach to using Twitter. I think I may well be adopting something very similar!
LikeLike
Thanks Simon. I’d love to chat to you about it if you do!
LikeLike
Wow – good effort! You might want to check-out this tool http://discovertext.com/sifter/ there are many others out there and I don’t actually use this one but this one does offers a free trial and sometimes competitions to win twitter data. Been meaning to email you about an event you might be interested in – so will do that now.
LikeLiked by 1 person
Thank you for sharing.
LikeLike
You’re welcome! I hope it is useful.
LikeLike